Poster
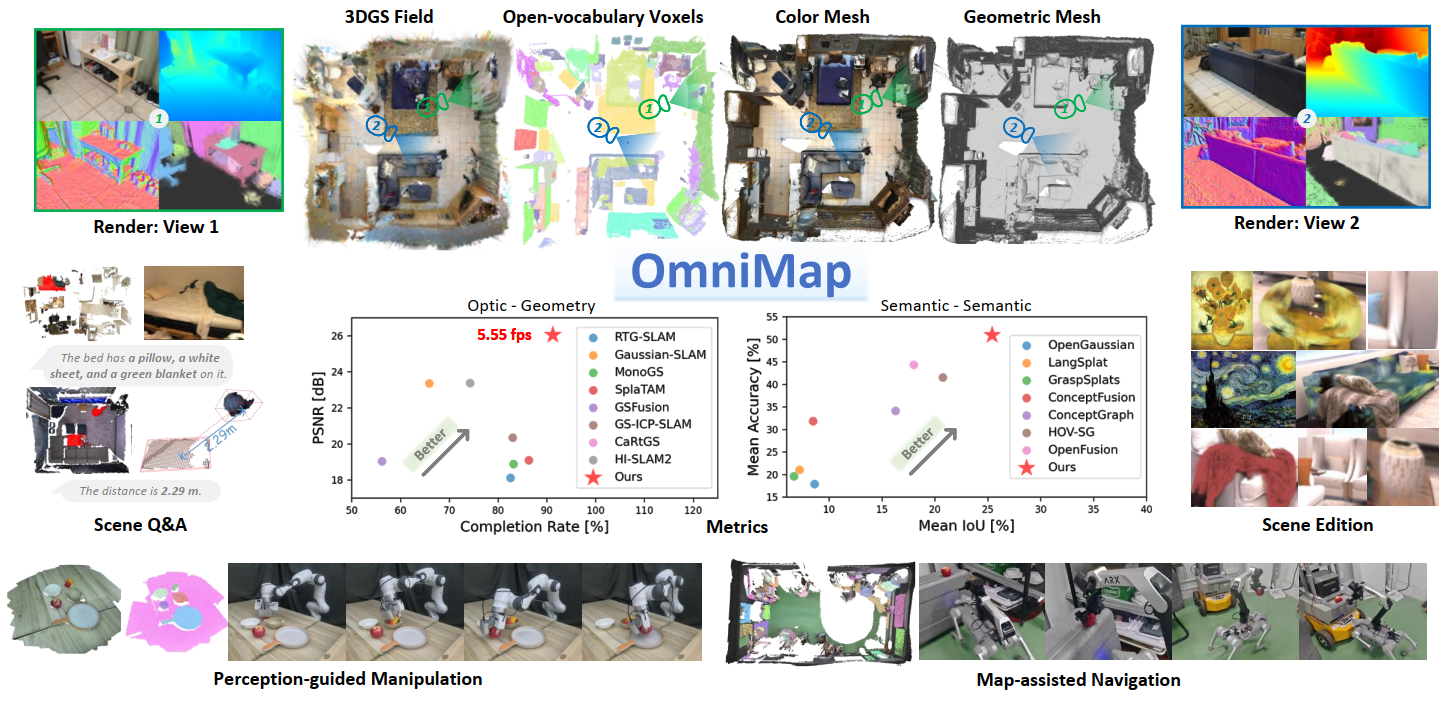
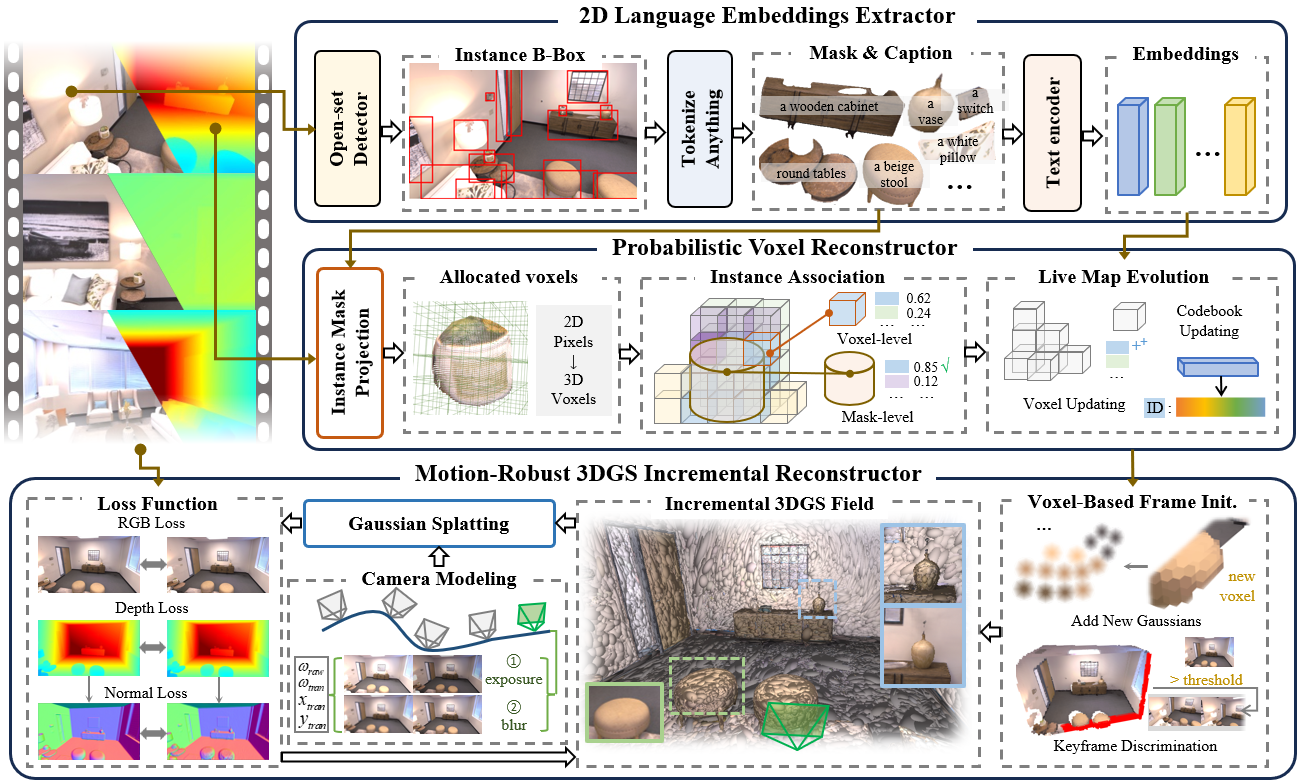
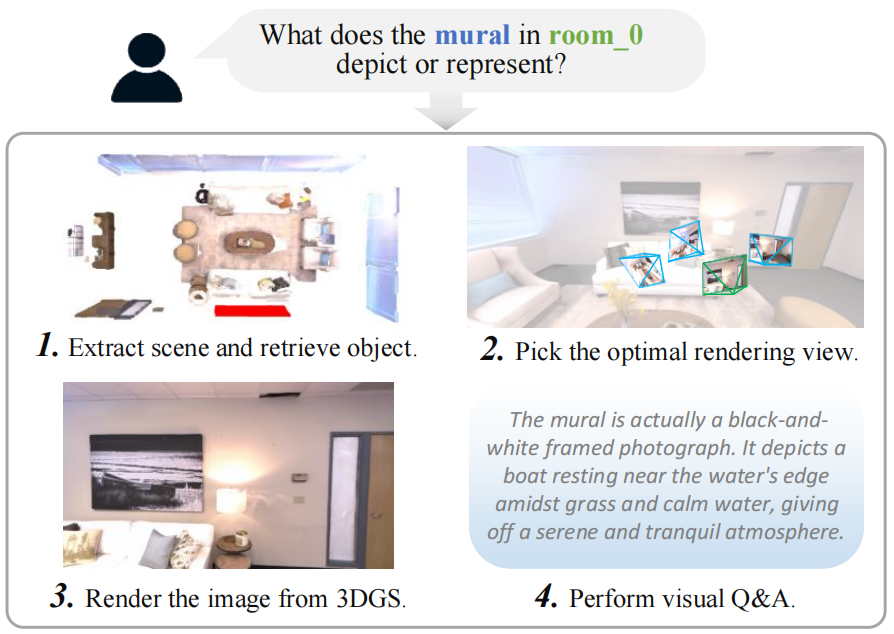
Robotic systems demand accurate and comprehensive 3D environment perception, requiring simultaneous capture of a comprehensive representation of photo-realistic appearance (optical), precise layout shape (geometric), and open-vocabulary scene understanding (semantic). Existing methods typically achieve only partial fulfillment of these requirements while exhibiting optical blurring, geometric irregularities, and semantic ambiguities. To address these challenges, we propose OmniMap. Overall, OmniMap represents the first online mapping framework that simultaneously captures optical, geometric, and semantic scene attributes while maintaining real-time performance and model compactness. At the architectural level, OmniMap employs a tightly coupled 3DGS–Voxel hybrid representation that combines fine-grained modeling with structural stability. At the implementation level, OmniMap identifies key challenges across different modalities and introduces several innovations: adaptive camera modeling for motion blur and exposure compensation, hybrid incremental representation with normal constraints, and probabilistic fusion for robust instance-level understanding. Extensive experiments show OmniMap’s superior performance in rendering fidelity, geometric accuracy, and zero-shot semantic segmentation compared to state-of-the-art methods across diverse scenes. The framework’s versatility is further evidenced through a variety of downstream applications including multi-domain scene Q&A, interactive edition, perception-guided manipulation, and map-assisted navigation.
Tips: please refresh the page if the display is incomplete
Visualisation of scene obtaind by different methods.




















Visualisation of scene obtaind by different methods.






















Visualisation of scene obtaind by different methods.









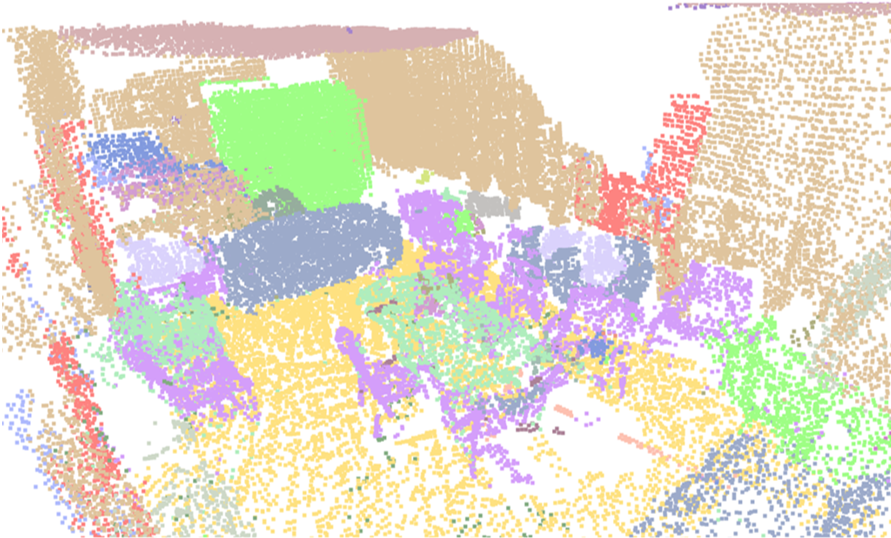






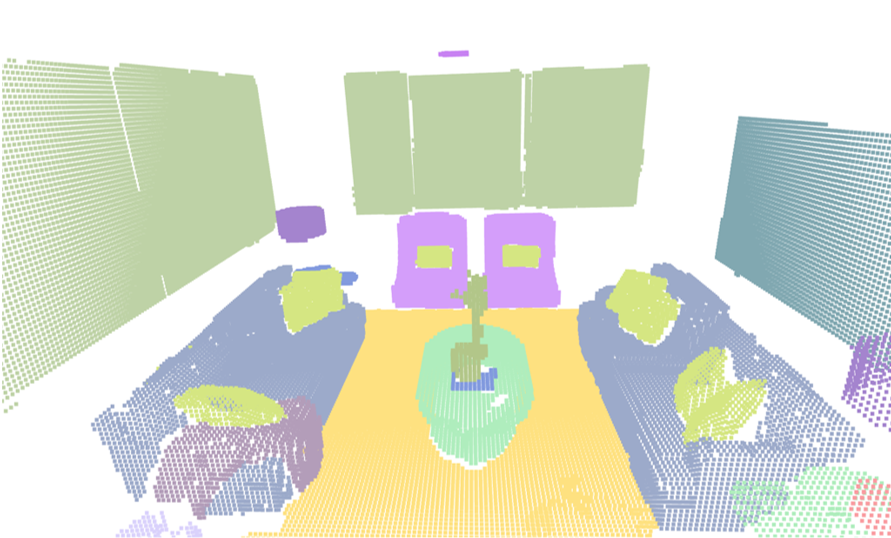


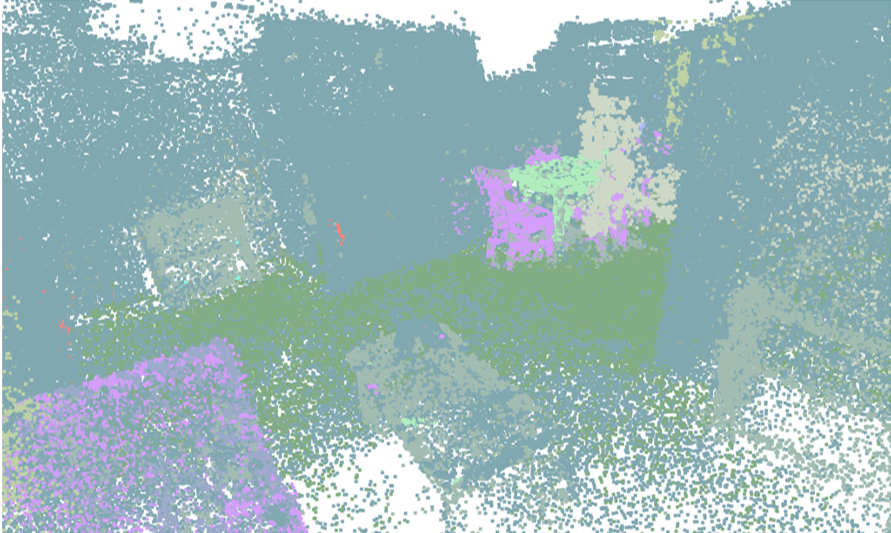




Tips: please click to view the video
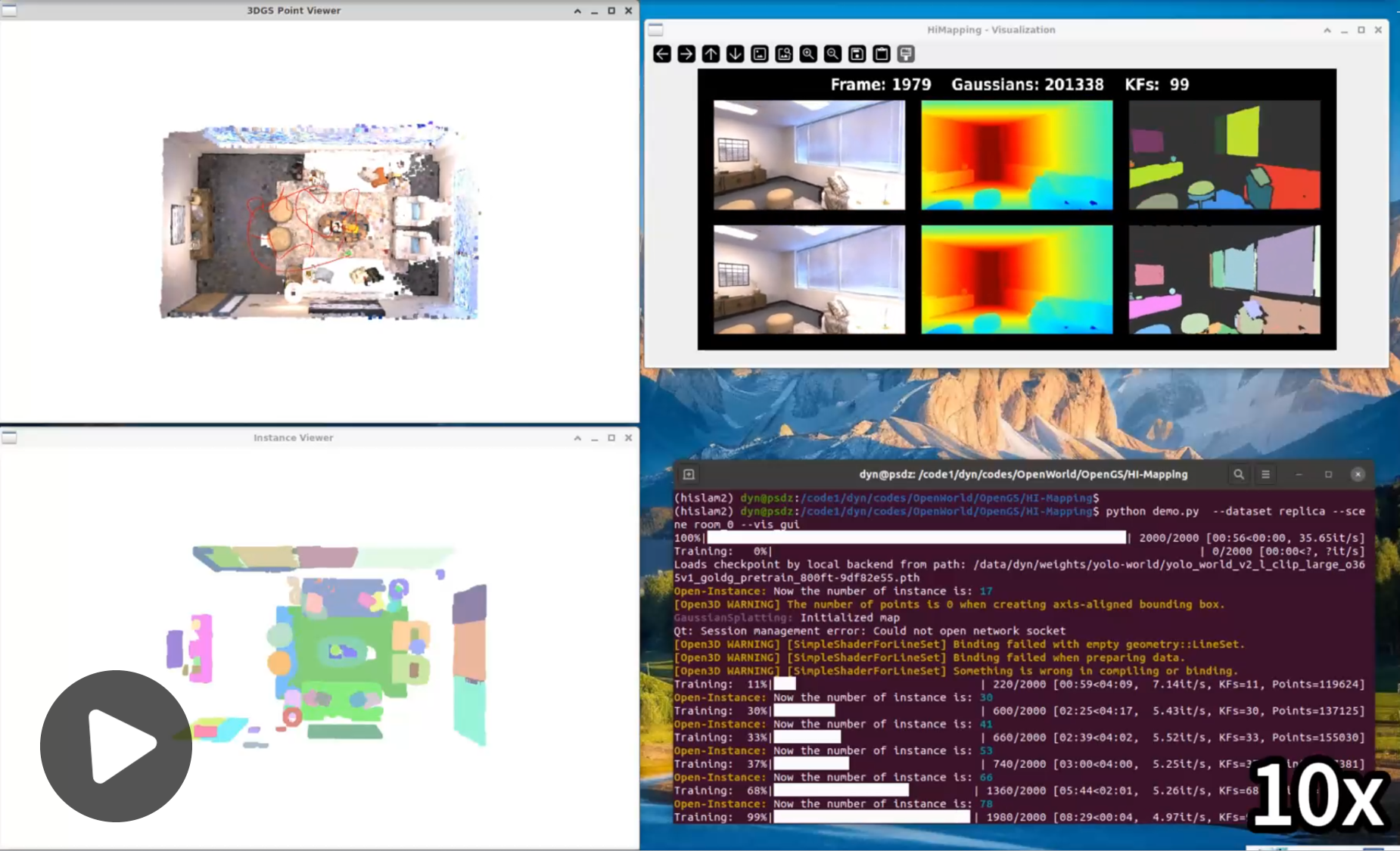
Replica-room_0

ScanNet-scene0106_00



Tips: please click to view the video

OmniMap supports robotic arm operations by reconstructing workspace optics, geometry, and semantics.
Tips: please click to view the video

OmniMap enables mobile robot navigation experiments.